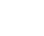OBJECTIFS DE LA FORMATION
Cette formation de 5 jours est une initiation avancée et intensive à Stable Diffusion, outil IA génératif et correctif d’images.
Stable Diffusion est la plateforme IA d’outils génératifs open source le plus puissant et flexible existant, et qui nécessite un apprentissage assez long.
En 5 jours on pourra parvenir à un bon niveau de compréhension et de maîtrise de Stable Diffusion, pour créer et transformer des images fixes :
- découvrir Stable Diffusion, sous ses différentes formes : SDXL, Flux.
- maîtriser la génération d’images avec ComfyUI, outil principal, à l’interface nodale complexe mais souple
- développer des prompts sophistiqués, les mélanger, utiliser des librairies et styles
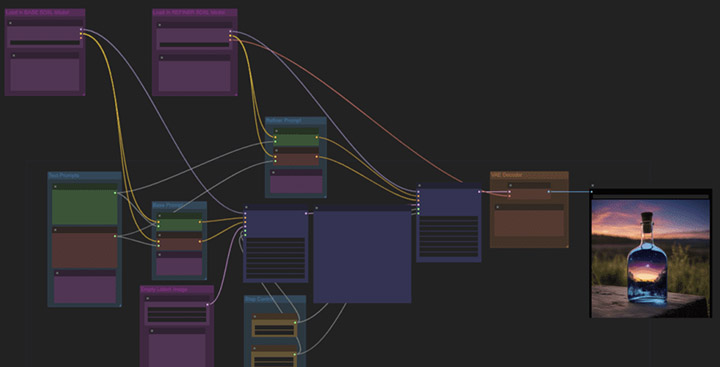
- utiliser InvokeAI, outil complémentaire parfait pour les retouches et composites complexes et créatifs
- utiliser ControlNet pour les poses et compositions et Ipadapter pour les styles
- utiliser PulID pour garder la consistance d’un personnage d’une génération à l’autre
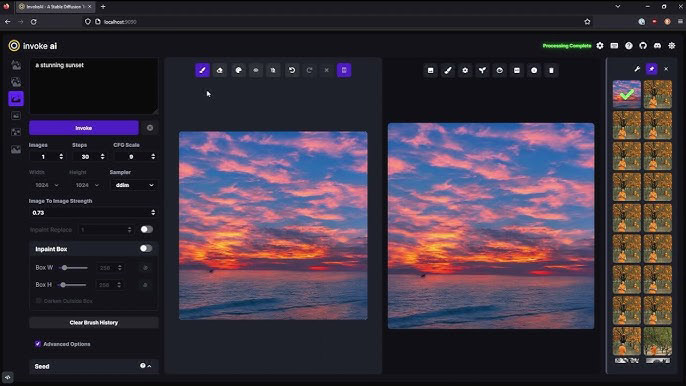
- Créer un Lora pour développer un style d’image ou générer des personnages consistants
La formation croisera prompts de textes imaginaires, références d’images réelles, stylisations, dessins et rendus non réalistes…
NOTA BENE : cette formation nécessite d’avoir déjà une pratique d’IA génératives (Dall-E, MidJourney…), idéalement de connaître des applications à interface nodale, ou au minimum d’être très l’aise avec les outils informatiques !

Objectifs de la formation :
- Installer et paramétrer ComfyUI, l’interface nodale
- Ecrire des prompts, de manière avancée
- Agrandir des images avec différentes méthodes
- Modifier, transformer une image
- Générer une image depuis un dessin
- Gérer des poses avec OpenPose
- Comprendre et utiliser Depth, Canny, Scribble
- Gérer ControlNet de manière avancée
- Savoir gérer la stylisation avec les Ipadapter
- Utiliser InvokeAI, l’outil parfait pour mieux contrôler ses créations
- Utiliser l’inpaint pour modifier profondément une image, réelle ou créée par IA
- Faire de l’Outpaint pour agrandir une image en créant de la matière
- Créer des composites complexes avec photobashing
- Intégrer des objets ou des personnages dans une image IA en respectant le style
- Réaliser des packshots automatiques et évolutifs de produits, parfums, voitures…
FORMATEUR Lionel Vicidomini, motion designer, graphiste 3D, enseignant et formateur, créateur bien connu de nombreux tutos de référence (sur Blender, Cinema 4D, Stable Diffusion…)

Présentation de l'outil
Stable diffusion est un outil open source et gratuit qui permet de générer des images à partir d’un texte descriptif (un modèle « text2image », comme par exemple les outils génératifs Dall-E ou MidJourney).

Stable Diffusion est actuellement le dernier outil encore Open Source… Contrairement à ses concurrents, Stable Diffusion est libre et gratuit. N’importe qui peut récupérer le code source de Stable Diffusion, le faire tourner en local sur son PC ou l’héberger sur un serveur web. Comme le code source est accessible, on peut modifier l’outil et l’adapter à ses besoins. Les concurrents MidJourney et Dall-E sont payants et ne peuvent pas fonctionner en local.
On étudiera Stable Diffusion sous différentes versions/interfaces, accompagné d’outils, scripts, complémentaires.
ComfyUI est une interface nodale, complexe mais très flexible pour générer des images. On construit des images en chaînant différents blocs (des nodes / nœuds). C’est l’interface la plus populaire et la plus puissante
InvokeAI ressemble plus à un mini-Photoshop. Nettement plus simple à utiliser que ComfyUI mais malgré tout extrêmement capable, il brille par sa capacité à permettre de modifier manuellement l’image générée par IA. On peut facilement faire du photobashing, étendre des générations, transformer des crayonnés en photo, puis les reprendre pour changer leur style etc.
Les LORA sont des mini-modèles qui se patchent au modèle principal et permettent d’orienter la génération dans une direction précise. On peut obtenir ainsi des styles de peintures, de dessin, de photo, ou alors ajouter des détails dans une image, ou obtenir des personnages consistants d’une génération à une autre etc…
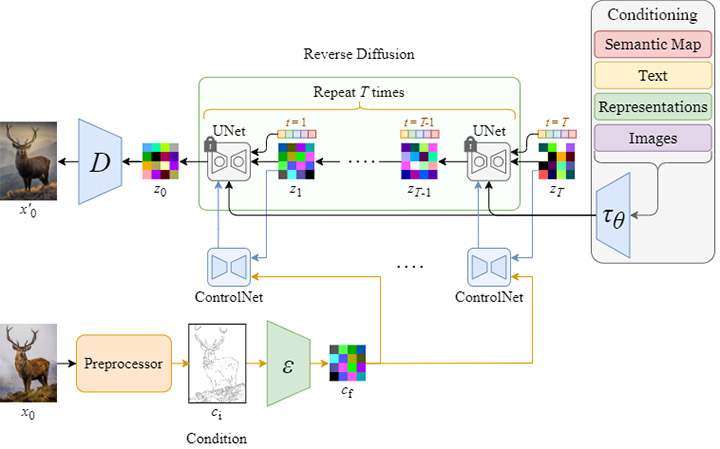
ControlNet est une technique dans Stable Diffusion qui permet de modifier le bruit initial, permettant par exemple de préciser des poses humaines, copier une composition d’une autre image, générer une image similaire,…
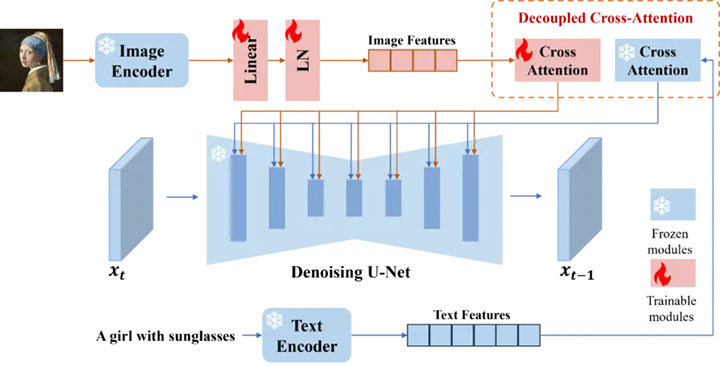
Ipadapter permet de « patcher » le modèle IA pour copier le style d’une image sur une nouvelle génération. On appelle ça également le « visual prompting » qui permet de créer des variations d’image, ou des fusions créatives de style.
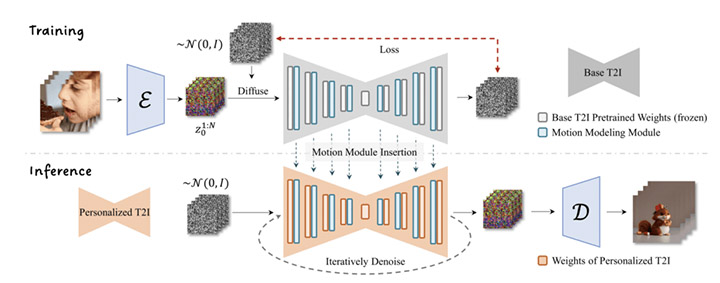
AnimateDiff est un module d’animation par prompt des images/modèles de Stable Diffusion pour produire des vidéos.
CONTENU COMPLET DE LA FORMATION
COMFY UI
Installation de ComfyUI
Pourquoi Comfy UI
Installation et configuration du manager
Nodes custom les plus fréquents
Découverte et prise en main de l’interface
Premières générations d’images
LE PROMPT
Comment écrire un prompt
Le checkpoint : utilisation de CivitAI pour découvrir et utiliser d’autres modèles
Concept du Token
Seed et Steps
Le Sampler
CFG
Emphase positive et négative
S’aider d’autres IA pour écrire des prompts
Récupérer un prompt depuis une image
Concaténation.
Combine.
Textual inversion
Installer des embeddings
AGRANDIR DES IMAGES
Upscaler
Latent space
High res fix
Ultimate Upscale
Combinaison de plusieurs méthodes
GENERATION DEPUIS UNE IMAGE OU UN DESSIN
Améliorer une image créée dans Txt2Image
Réparation de défauts avec Inpaint
Ajout de détails avec Sketch et Inpaint Sketch

Depuis une image externe
Ajout de détails
Changement de style
Agrandir une image
Loopback : itérer des créations depuis un croquis ou crayonnage
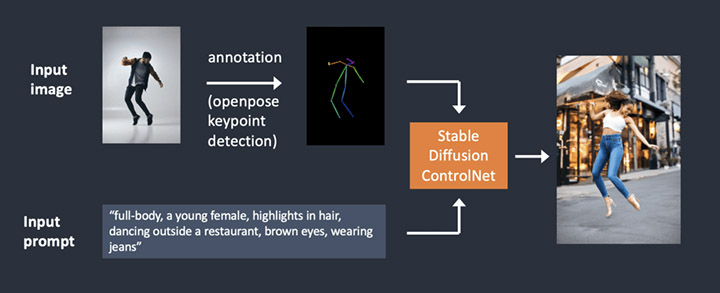
CONTROL NET
Qu’est-ce que ControlNet ?
OpenPose
Récupérer des poses de photos ou d’image
Récupérer des poses d’autres logiciels ou source
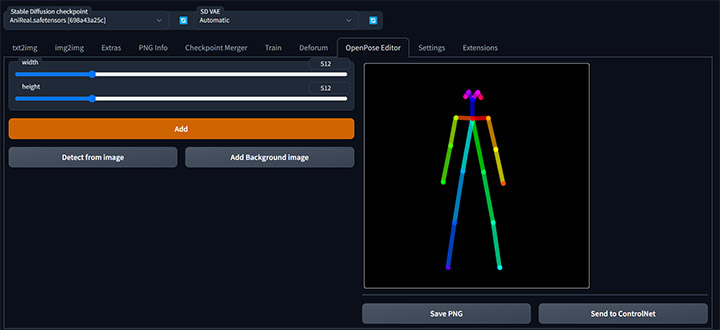
Créer sa pose ou la modifier avec l’openpose editor
Créer une pose depuis un autre logiciel
Scribble, SoftEdge, Canny et Lineart
Transformer un dessin en photo
Transformer une photo en dessin
Récupérer les expressions d’un visage
Depth
Récupérer un contour, une forme
Donner vie à un paysage
Seg
Changer un paysage
Changer un intérieur
Rajouter des détails
Contrôler totalement les images grâce aux masques
Ipadapter
Récupérer un personnage précis pour en faire des variations
Pour varier les angles de vue

Style
Appliquer le style d’une image sur une autre image
Créer des styles hybrides
Appliquer la palette chromatique d’une image sur une autre
Combiner plusieurs ControlNet
Pour des poses et expressions précises
Faire du photobashing

INVOKEAI
InvokeAI, l’outil parfait pour intervenir manuellement dans les créations IA.
Composite complexe en utilisant le photobashing
Extension de décor avec l’outpaint
Ajout de personnages ou objets à une image en respectant le style
Enrichissement de détail en esquissant des contours
CREER SON PROPRE LORA
Pour créer un style particulier d’image
Pour obtenir des personnages consistants d’une génération à une autre

CONDITIONS DE LA FORMATION
MOYENS TECHNIQUES
6 stagiaires maximum. 1 station Windows avec processeur et carte graphique puissants, 64 Go de RAM, écran 27 pouces. Tablette graphique.
PARTICIPANTS
Graphistes, responsables communication, truquistes, photographes, artistes, réalisateurs.rices, DA, technicien.ne.s, toute personne ayant besoin de se former à la génération et transformation d'images avec l'outil IA Stable Diffusion.
NIVEAU REQUIS
Bonne connaissance de l’informatique. Notions de graphisme (profondeur d’image, pixel, formats, ratios...). Culture artistique. Pratique d'IA génératives (Midjourney, DallE...). Idéalement, pratique d'un outil nodal (3D, VFX)...
ACCESSIBILITÉ
Nos formations sont accessibles et aménageables pour les personnes en situation de handicap. Fauteuils roulants autorisés en largeur maxi 70cm. Pour tout handicap, auditif, visuel ou autre, merci de nous contacter pour les aménagements possibles.
VALIDATION DES ACQUIS
Contrôle continu tout au long de la formation, exercé par le formateur et supervisé par la responsable pédagogique. Délivrance d'un Certificat de Validation des Acquis de Formation. (en savoir plus)
MODALITES D'ORGANISATION
Formation présentielle, en nos locaux, 13 rue Desargues, 75011 Paris.
MOYENS ET MODALITES PEDAGOGIQUES
Une salle de formation avec tableau blanc, un poste informatique pour chaque apprenant, un poste informatique vidéo-projeté pour les formateurs, avec accès internet et imprimante partagée. Alternance de séquences théoriques et d'exercices d'application réelle. Les exercices sont réalisés sous la supervision des formateurs, dans une logique d'apprentissage des compétences et d'autonomie progressive des apprenants. Des exercices plus longs et synthétiques permettent de reprendre un ensemble de compétences dans des cas pratiques types des métiers et compétences concernés, et s'assurer de leur acquisition par les apprenants.
SUPPORT DE COURS
1 mémo sur Stable Diffusion.
SUIVI DE STAGE
Gratuit par email
RESP. PÉDAGOGIQUE
James Simon
FORMATEUR
Professionnel en activité, expert reconnu dans son domaine, animant régulièrement des formations.
LABELS QUALITÉS
Centre certifié Qualiopi (certification nationale) / certifié ISQ-OPQF / référencé Data-Dock / centre certifié Adobe / Maxon / Blackmagic Design / centre de test Certiport